Technorati tags are an interesting idea, but it falls apart under real world conditions.
Embedded Tagging Only
Because the author of a blog is the only one who can inject tags, this presents a wide open opprotunity for spammers to turn Technorati into a spam search engine - a spamgine? See Om Malik's post for more details.
The author of the post is unlikely to search and find all applicable blogs, as they just want to get the post written. Thus it's unlikely to ever become a majority action.
Tags are vague
Since any arbitrary word can get used as a tag, the probability is that the need for disambiguation will overwhelm their utility. Coupled with the lack of the AND operator at technorati, this becomes a fatal flaw in itself.
No markup tags
The author of a post is probably the last one you want to criticize the post, which is where tagging can be its most powerful. If the rest of us could tag posts, it would be far more likely to be an accurate (or somewhat fair) representation of what a post was really about. Even a popularity contest is going to be more representative than self nomination and promotion.
Tuesday, February 28, 2006
Hyperwords and Collaboration
Collaboration: 1970s
When I went to school, we had a model of collaboration based on an old technology, paper. We started with an existing document, and added information to it. This would transform the document from let's say a piece of ruled paper, into an essay. Or in other cases it would transform a quiz or test into our completed sheet, which would then be forwarded for further processing.
The teacher would then read the document, circle or highlight, or otherwise add markup and notations to help indicate areas of improvement, correction, or other information. The document would then be sent back to the student to complete the feedback loop.
It was a simple, effective workflow, with millenia of experience embedded into it.
Collaboration: Web 2.0
Create a document in your editor of choice. Cut and paste and markup and highlight your text to suit your audience. Publish this document in HTML to a web server.
Since HTML doesn't allow external markup, the choices for your collaborators become:
The ability to add markup to a document is one of the key things that prevents Web 2.0 from really being a "live web". We can plaster our servers with pages, but no true markup is possible. The words on web pages are always always static, because they've been published.
HyperWords
Doc Searls solicited comments about the HyperWords plugin. With the above view of what it really takes to interact with a document, and the words within... I'd have to say it doesn't fit the bill. This plugin, though clever, and apparently a great tool, does nothing to change the read-only nature of the web (even the "Live Web").
I'm already using "search google for" in Firefox (highlight text, then right-click) as a very powerful cross referencing tool. The problem is that the cross reference doesn't persist. There's no permanent connection made between the document and the found links. In fact, there's no way to make any persistent markup of a web page in a browser. The browser is read-only, and is likely to remain that way for the duration.
Towards a writeable web
We do need the ability to make this stuff interactive. If I see something wrong with a posting, I should be able to put a post-it note up there, somehow. Even if nobody else can see it, it might be helpful for me. I believe that this markup of hypertext would be a quite valueable tool for others as well.
Any tool which helps transform the web from read-only to truely read-write in a sane process gets my vote.
I'm a hacker at heart, I'm willing to discuss the mechanics of this with anyone.
Notes:
Yes, I know that inviting markup invites grafitti, spam, etc. That's what IDENTITY is for, to help limit those the application of markup to those with non-bad (or perhaps good) reputations.
Yes, I know it'll require a new protocol to support annotation of external documents. HTML is embedded only, we need to rethink this.
I'm one lone voice in the wilderness, trying to find others who share my viewpoint. Can the live web help?
--Mike--
Technorati tag: hyperwords
When I went to school, we had a model of collaboration based on an old technology, paper. We started with an existing document, and added information to it. This would transform the document from let's say a piece of ruled paper, into an essay. Or in other cases it would transform a quiz or test into our completed sheet, which would then be forwarded for further processing.
The teacher would then read the document, circle or highlight, or otherwise add markup and notations to help indicate areas of improvement, correction, or other information. The document would then be sent back to the student to complete the feedback loop.
It was a simple, effective workflow, with millenia of experience embedded into it.
Collaboration: Web 2.0
Create a document in your editor of choice. Cut and paste and markup and highlight your text to suit your audience. Publish this document in HTML to a web server.
Since HTML doesn't allow external markup, the choices for your collaborators become:
- Copy the document, and embed markup in the document
- Point to the document you want to talk about, copying sections to try to bring focus to the areas of interest
- Point ot the document, and just write about it in general terms.
The ability to add markup to a document is one of the key things that prevents Web 2.0 from really being a "live web". We can plaster our servers with pages, but no true markup is possible. The words on web pages are always always static, because they've been published.
HyperWords
Doc Searls solicited comments about the HyperWords plugin. With the above view of what it really takes to interact with a document, and the words within... I'd have to say it doesn't fit the bill. This plugin, though clever, and apparently a great tool, does nothing to change the read-only nature of the web (even the "Live Web").
I'm already using "search google for" in Firefox (highlight text, then right-click) as a very powerful cross referencing tool. The problem is that the cross reference doesn't persist. There's no permanent connection made between the document and the found links. In fact, there's no way to make any persistent markup of a web page in a browser. The browser is read-only, and is likely to remain that way for the duration.
Towards a writeable web
We do need the ability to make this stuff interactive. If I see something wrong with a posting, I should be able to put a post-it note up there, somehow. Even if nobody else can see it, it might be helpful for me. I believe that this markup of hypertext would be a quite valueable tool for others as well.
Any tool which helps transform the web from read-only to truely read-write in a sane process gets my vote.
I'm a hacker at heart, I'm willing to discuss the mechanics of this with anyone.
Notes:
Yes, I know that inviting markup invites grafitti, spam, etc. That's what IDENTITY is for, to help limit those the application of markup to those with non-bad (or perhaps good) reputations.
Yes, I know it'll require a new protocol to support annotation of external documents. HTML is embedded only, we need to rethink this.
I'm one lone voice in the wilderness, trying to find others who share my viewpoint. Can the live web help?
--Mike--
Technorati tag: hyperwords
Sunday, February 26, 2006
Embedded Keywords
We're straddled with few ways of navigating the world wide web. Google and its kin are all based on the concept of keyword searches to dig through massive databases retrieved by spidering.
The interface we're given to try to mine this data is a keyword search, with modifiers. This is great if you're looking for the most popular use of a word, but if you're looking for the unpopular, you're screwed.
People tend to use the words they already seen used to describe a concept or viewpoint, or meme. Over time, because of our heavy use of keyword searches, the meme tends to monopolize certain keywords. This leads to the exclusion of other memes that discuss the same subject.
Keyword search then tends to result in an echo chamber, where a majority viewpoint gets found first, and much more frequently. It's a popularity contest if you will, for ownership of the keywords.
Language gets used as a tool of thought control if you think about it long enough. If you can invent a neologism, and maintain control over it's definition, you've just bought part of the language... now that's power!
There are alternatives, conversation unmediated by machine is the best. If you give authority to the machine, you end up thinking like one. Do not go gentle into that good night.
The interface we're given to try to mine this data is a keyword search, with modifiers. This is great if you're looking for the most popular use of a word, but if you're looking for the unpopular, you're screwed.
People tend to use the words they already seen used to describe a concept or viewpoint, or meme. Over time, because of our heavy use of keyword searches, the meme tends to monopolize certain keywords. This leads to the exclusion of other memes that discuss the same subject.
Keyword search then tends to result in an echo chamber, where a majority viewpoint gets found first, and much more frequently. It's a popularity contest if you will, for ownership of the keywords.
Language gets used as a tool of thought control if you think about it long enough. If you can invent a neologism, and maintain control over it's definition, you've just bought part of the language... now that's power!
keywords embedded in meme,
expressing the very same theme,
working together
through google and others,
framing the limits of dreams
There are alternatives, conversation unmediated by machine is the best. If you give authority to the machine, you end up thinking like one. Do not go gentle into that good night.
HTML - The Embedded Cancer
HTML is a great acronym if you like great lawyer speak. It's a term which has now monopolized the concept of markup, and is a cancer!
HTML is an EMBEDDED markup language. This means that the markup has to be intermixed with the text it is meant to mark up. This direct physical linkage, embedding, of the markup is great of you happen to be the owner of the document, and have the tools to hide the complexity of it's internal representation, but for everyone else, it's hell.
What HTML should been, is a markup language for hypertext. It should allow the markup of an existing SEPARATE document, by reference. Ted Nelson tried very hard to get this idea across to the masses, but when the critical moment came, Tim Berners Lee took the easy way out, and we're all screwed, even though most of us don't even know it.
There are a great many things that are broken as a result of this singularly bad choice. We're forced to rely on spiders to find documents on the world wide web. We have no ability to add commentary directly on top of other people's work, except by extraordinary measures, which break copyright rules.
The embedded nature of HTML has limited our range of thought. It is an example of how the limitations of language impose limitations of range of thought. If you can't imagine being able to highlight a section of someone's blog posting in yellow, with a hyperlink to something else, and a note that says something about the connection, you won't ever miss it.
HTML is evil. I'm open to any discussion about alternatives.
HTML is an EMBEDDED markup language. This means that the markup has to be intermixed with the text it is meant to mark up. This direct physical linkage, embedding, of the markup is great of you happen to be the owner of the document, and have the tools to hide the complexity of it's internal representation, but for everyone else, it's hell.
What HTML should been, is a markup language for hypertext. It should allow the markup of an existing SEPARATE document, by reference. Ted Nelson tried very hard to get this idea across to the masses, but when the critical moment came, Tim Berners Lee took the easy way out, and we're all screwed, even though most of us don't even know it.
There are a great many things that are broken as a result of this singularly bad choice. We're forced to rely on spiders to find documents on the world wide web. We have no ability to add commentary directly on top of other people's work, except by extraordinary measures, which break copyright rules.
The embedded nature of HTML has limited our range of thought. It is an example of how the limitations of language impose limitations of range of thought. If you can't imagine being able to highlight a section of someone's blog posting in yellow, with a hyperlink to something else, and a note that says something about the connection, you won't ever miss it.
HTML is evil. I'm open to any discussion about alternatives.
Discontent
I'm pissed about a number of things, mostly my own ability to articulate things, aided and abetted by the persistent doubt of actually making a difference anyway.
I'm going to make a series of posts, one per subject, so that if actual discussion follows... it won't be muddled up.
I'm going to make a series of posts, one per subject, so that if actual discussion follows... it won't be muddled up.
Friday, February 24, 2006
Clue train, redux
As pointed to a few days ago, over at Head Lemur's: Raving Lunacy, Marketing is a Disease
Wow! This has the barbaric yalp written all over it, and it's all dead true!
Good stuff, part of my daily reads.
--Mike--
Marketeers talk about control and spin. Traditional Marketing Wisdom stated that a bad customer experience would only lose you 7 customers. That was in the days of Monologue. This is age of Dialogue. The Internet and Blogs can cost you all of them. This is age of Dialogue. Genuine Dialogue. Every company who has tried ghost blogs has had their asses handed to them. We are smart and getting smarter every day. Our bullshit detectors will ferret you out and thousands of voices will point and laugh. You cannot spin your way out of this.
Wow! This has the barbaric yalp written all over it, and it's all dead true!
Good stuff, part of my daily reads.
--Mike--
"no-feedback" nonsense
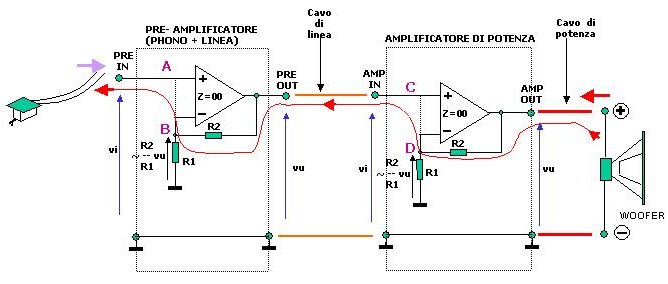
I saw this diagram on this page found via Digg, which is a pretty good source of fresh new stuff to read about. I wanted to read about the big subwoofers... which are good to gawk at.
The part that gets in my craw is the misunderstanding of feedback.
The quote that goes with it the diagram contains an error
FIGURE BELOW: shows the Electromotive Energy produced by the speaker that thru the F.B. path reaches even your turntable cartridge. Amp and preamp are shown as Operational Amplifier for semplicity. Any linear amplifier is by definition an Operational amplifier with linear trasfer function used as a constant multiplier.There is a hidden assumption, left unwritten. This is that the transfer function is a constant multiplier in both directions. It's not true. The forward transfer function is almost perfectly a constant gain (multiplier), but the reverse function isn't.
The amplifier uses a low impedance output to supply whatever current is necessary to the load, with the feedback resistor along for the ride. The result is that any possible contribution to the current through the feedback resistor is shunted through the output stage to ground. This means that even a single stage amplifier will provide attenuations on order of Rout/Rfeedback * Open Loop Gain. This means that even a single stage is sufficient to completely isolate an input.
The insistance on "no-feedback" amplification makes for a nice market niche, but is not based on fact.
--Mike--
Thursday, February 23, 2006
The need for editing
Scott Adams discusses blogging in the form of a list of class notes. The one that caught my eye was
I respectfully disagree. An audience of regulars might appreciate and understand where things are going in a spur of the moment post. However, in the case of "small bloggers" or new audiences, it's less likely that there will be sufficient patience to overcome the any lapses in clarity.
I cringe when I realize I've let something go too soon. I'm tempted to re-read everything and to clean it all up, but somehow I know that's not right either.
It's better to take a few minutes, read what you're about to submit aloud, and make sure you really want to say it that way.
Take the time, it'll help us all out.
Thank you for your time and attention.
--Mike--
Half-Baked Thoughts. Nobody's going to pounce on you for putting your half-baked thoughts on your blog. People may disagree, or help you see some flaws, but almost always with the understanding that they are in your house as a guest.
I respectfully disagree. An audience of regulars might appreciate and understand where things are going in a spur of the moment post. However, in the case of "small bloggers" or new audiences, it's less likely that there will be sufficient patience to overcome the any lapses in clarity.
I cringe when I realize I've let something go too soon. I'm tempted to re-read everything and to clean it all up, but somehow I know that's not right either.
It's better to take a few minutes, read what you're about to submit aloud, and make sure you really want to say it that way.
Take the time, it'll help us all out.
Thank you for your time and attention.
--Mike--
Wednesday, February 22, 2006
Virtual Machines, the future of security
The purpose of an operating system is to manage the resources of a computer. Over time, market competition has lead to the inclusion of a number of new components into standard distributions of operating systems. It is now common for such a system to include a network stack, at least one scripting language, a web browser, and email client. A server would also include services such as file sharing, authentication, web and ftp services, and more.
Windows, Mac OS, and Linux have similar security models. It's all about the user. Once the user signs in, it is assumed they should be allowed to do anything they have permission to do. The user is expected to be judicious in their choices of actions.
Unless special precautions are taken, programs run with identical permissions to the user which they are working on behalf of. This means that the user is forced to trust a program in order to use it. There is simply no other option for the average user. This need to trust code is implicit in the security model. It's so deeply embedded in our conception that it takes people by surprise when you point it out. This need to absolutely trust code is a very corrosive force, and is responsible for most of the security problems that plague PCs today.
This is how we get virii and other problems that keep cropping up, in spite of virus scanners, etc. Once lanched, a virus has essentially full run of a PC, which it can use to spread itself, or to use for its payload program.
Most efforts these days are being directed towards what I consder to be a stopgap measure. This is to try to limit the user to running only trustworthy code. The decision is made that some programmers are deemed trustworthy, and given cryptographic keys to "sign" a piece of code.
The signatures on a piece of code can thus be checked for validity before it is executed. This can help prevent tampering with the code, so it does help security, a bit.
However, this is not a long term solution, though many are otherwise convinced. The problem is that any bug, anywhere in the program can be used to attack the system. Consider that a workstation with the standard load might have a million lines of code, with perhaps 20 different services running at any give time. If any of these systems have a bug, it may be possible to exploit it, and take over the system.
--
I've been digging around the question of PC security for a while now since my Windows Apocalypse. I'm now convinced the only way out is to use a classic solution, and to head in the opposite direction.
Instead of accepting more and more code as "trusted", we need to adopt the philosophy that NOTHING should be trusted, unless absolutely necessary. Even device drivers shouldn't be trusted.
IBM engineers in the 1960s utilized the Virtual Machine concept to make scarce resources available to Operating System developers. They did this by offering what appeared to be a complete machine to each program to be run. This allowed the development of new operating systems on hardware that didn't exist yet, and eliminated the need to give each and every programmer at least one mainframe of their own.
The net result is that each and every virtual machine created is insulated from the hardware, and from every other virtual machine. It's practically impossible for a process inside a virtual machine to do any harm to the outside environment. Because of this, you don't have to trust the code you run, you can just contain it in a Virtual Machine.
The adoptation of Java, and more recently, ".net" are both steps in the right direction. They place code into a "sandbox", and limit access. However the permissions are course, and the idea of trusted code creeps in, thus limiting the effectiveness of the sandbox.
Bochs, Plex86, VMware, and "Virtual Server" are all adaptations of this strategy. They emulate a complete PC (or substantial portion thereof) to allow a complete operating system to run inside a virtual machine. This makes it possible to test out new OSs, do development, etc... much in the same way the IBM programmers back in the 1960s were allowed to do so, even though it's likely the programmers now can afford multiple computers. It's much easier to debug from an environment that doesn't have to be rebooted all the time. ;-)
The recent arrival of the "browser appliance" as a safer way to surf the web is an example of running an application insider a sandbox, albeit a very elaborate one. The speed of the virtualization on current stock hardware will be less that idea, due to some architectural limitations of the 386 heritage.
Recent announcements by both Intel and AMD of hardware support for virtualization are very encouraging. It was this type of hardware support that made the VM/370 system feasable in the 1960s. This will allow virtualization with almost no performance penalty on future machines.
The next step will be lightweight operating systems optimized to run inside virtual machines. Because the virtual machine environment provided is completely uniform, the number of drivers required to interact with it can be reduced almost to zero. As time goes on, even this overhead can be reduced by the use of run-time systems, which are tailored for specific uses.
We may start to see the distribution of applications inside of their own operating systems as a convinient means of making sure that everything necessary for the application gets included.
All of this points to a future which might make a mainframe programmer smile with the recognition that it's all happening again, but slightly differently... and they'd be right. The concept of trusted code will die, at least until the sequel. ;-)
Eventually, we'll get to the point where no application needs to be trusted. Most of the operating system itself doesn't need to be trusted, so it won't be. The long term result is to have one, and only one, piece of trusted code in the system... a microkernel virtual machine manager. It will be the only piece of code running on the bare metal. Device drivers, security algorithms, everything else will run in its own virtual environment, in complete isolation.
Only then will security be sufficiently fixed that I can relax, or so I hope.
That's my prediction, I welcome all criticism and discussion.
--Mike--
Windows, Mac OS, and Linux have similar security models. It's all about the user. Once the user signs in, it is assumed they should be allowed to do anything they have permission to do. The user is expected to be judicious in their choices of actions.
Unless special precautions are taken, programs run with identical permissions to the user which they are working on behalf of. This means that the user is forced to trust a program in order to use it. There is simply no other option for the average user. This need to trust code is implicit in the security model. It's so deeply embedded in our conception that it takes people by surprise when you point it out. This need to absolutely trust code is a very corrosive force, and is responsible for most of the security problems that plague PCs today.
This is how we get virii and other problems that keep cropping up, in spite of virus scanners, etc. Once lanched, a virus has essentially full run of a PC, which it can use to spread itself, or to use for its payload program.
Most efforts these days are being directed towards what I consder to be a stopgap measure. This is to try to limit the user to running only trustworthy code. The decision is made that some programmers are deemed trustworthy, and given cryptographic keys to "sign" a piece of code.
The signatures on a piece of code can thus be checked for validity before it is executed. This can help prevent tampering with the code, so it does help security, a bit.
However, this is not a long term solution, though many are otherwise convinced. The problem is that any bug, anywhere in the program can be used to attack the system. Consider that a workstation with the standard load might have a million lines of code, with perhaps 20 different services running at any give time. If any of these systems have a bug, it may be possible to exploit it, and take over the system.
--
I've been digging around the question of PC security for a while now since my Windows Apocalypse. I'm now convinced the only way out is to use a classic solution, and to head in the opposite direction.
Instead of accepting more and more code as "trusted", we need to adopt the philosophy that NOTHING should be trusted, unless absolutely necessary. Even device drivers shouldn't be trusted.
IBM engineers in the 1960s utilized the Virtual Machine concept to make scarce resources available to Operating System developers. They did this by offering what appeared to be a complete machine to each program to be run. This allowed the development of new operating systems on hardware that didn't exist yet, and eliminated the need to give each and every programmer at least one mainframe of their own.
The net result is that each and every virtual machine created is insulated from the hardware, and from every other virtual machine. It's practically impossible for a process inside a virtual machine to do any harm to the outside environment. Because of this, you don't have to trust the code you run, you can just contain it in a Virtual Machine.
The adoptation of Java, and more recently, ".net" are both steps in the right direction. They place code into a "sandbox", and limit access. However the permissions are course, and the idea of trusted code creeps in, thus limiting the effectiveness of the sandbox.
Bochs, Plex86, VMware, and "Virtual Server" are all adaptations of this strategy. They emulate a complete PC (or substantial portion thereof) to allow a complete operating system to run inside a virtual machine. This makes it possible to test out new OSs, do development, etc... much in the same way the IBM programmers back in the 1960s were allowed to do so, even though it's likely the programmers now can afford multiple computers. It's much easier to debug from an environment that doesn't have to be rebooted all the time. ;-)
The recent arrival of the "browser appliance" as a safer way to surf the web is an example of running an application insider a sandbox, albeit a very elaborate one. The speed of the virtualization on current stock hardware will be less that idea, due to some architectural limitations of the 386 heritage.
Recent announcements by both Intel and AMD of hardware support for virtualization are very encouraging. It was this type of hardware support that made the VM/370 system feasable in the 1960s. This will allow virtualization with almost no performance penalty on future machines.
The next step will be lightweight operating systems optimized to run inside virtual machines. Because the virtual machine environment provided is completely uniform, the number of drivers required to interact with it can be reduced almost to zero. As time goes on, even this overhead can be reduced by the use of run-time systems, which are tailored for specific uses.
We may start to see the distribution of applications inside of their own operating systems as a convinient means of making sure that everything necessary for the application gets included.
All of this points to a future which might make a mainframe programmer smile with the recognition that it's all happening again, but slightly differently... and they'd be right. The concept of trusted code will die, at least until the sequel. ;-)
Eventually, we'll get to the point where no application needs to be trusted. Most of the operating system itself doesn't need to be trusted, so it won't be. The long term result is to have one, and only one, piece of trusted code in the system... a microkernel virtual machine manager. It will be the only piece of code running on the bare metal. Device drivers, security algorithms, everything else will run in its own virtual environment, in complete isolation.
Only then will security be sufficiently fixed that I can relax, or so I hope.
That's my prediction, I welcome all criticism and discussion.
--Mike--
Dave's been outdone!
I know Dave hates is allergic to marketers, but he's been outdone by this post over at Raving Lunacy.
Tuesday, February 21, 2006
Homeless photos
If you're looking for actual pictures of people who don't have a home... try this google image search this entry isn't about them. --Mike (May 10, 2006)
It's sad when a portrait loses it's home. Through the passage of time, memories fade, people die, and the photos lose their connections, they become homeless photos.Noran's mom had a special fondness for adopting homeless photos. She thought it was a very sad thing.
I find that the photos with a person happy and full of life make me feel good, wondering what they did, what joys they had in their lives. On the other had, not even having a name to go with the face, not having any other connection to the scene depicted, makes one contemplate the finite nature of life.
I'm worried that my collection of photos will eventually go homeless as well. It doesn't help that they're digital photos, and thus have an especially tenuous footing in the world. They live an ephemeral existence, mostly as magnetic fields on spinning platters, or sometimes as patters burned by a laser on DVD's.
I don't have names on any of them... I have no good reason for this. I've been doing a fairly good Metadata Advocate imitation as of late... it's especially hypocritcal of me to not do this simple thing for my photos, to help them from becoming homeless orphans.
From their view, the lucky ones get seen by family and friends on Flickr, my home page, or on South Shore by my fellow commuters. Most of them just get seen once or twice by me before going into the archives.
Homeless photos are a reminder of all passing before the sands of time. Only through effort do they continue to exist, to be shared and spread joy. Time is precious, please enjoy what you have. Please also take the time to name the people, to help give a little more connection, a little more life, to the photos and stories you share.
--Mike--
PS: Noran found this nice collection of found photos.
It's sad when a portrait loses it's home. Through the passage of time, memories fade, people die, and the photos lose their connections, they become homeless photos.Noran's mom had a special fondness for adopting homeless photos. She thought it was a very sad thing.
I find that the photos with a person happy and full of life make me feel good, wondering what they did, what joys they had in their lives. On the other had, not even having a name to go with the face, not having any other connection to the scene depicted, makes one contemplate the finite nature of life.
I'm worried that my collection of photos will eventually go homeless as well. It doesn't help that they're digital photos, and thus have an especially tenuous footing in the world. They live an ephemeral existence, mostly as magnetic fields on spinning platters, or sometimes as patters burned by a laser on DVD's.
I don't have names on any of them... I have no good reason for this. I've been doing a fairly good Metadata Advocate imitation as of late... it's especially hypocritcal of me to not do this simple thing for my photos, to help them from becoming homeless orphans.
From their view, the lucky ones get seen by family and friends on Flickr, my home page, or on South Shore by my fellow commuters. Most of them just get seen once or twice by me before going into the archives.
Homeless photos are a reminder of all passing before the sands of time. Only through effort do they continue to exist, to be shared and spread joy. Time is precious, please enjoy what you have. Please also take the time to name the people, to help give a little more connection, a little more life, to the photos and stories you share.
--Mike--
PS: Noran found this nice collection of found photos.
Monday, February 20, 2006
Dotster, SSL support needs work
I recently ordered an SSL certificate for the first time ever. I decided to order it through Dotster, because I've had good luck with them in the past.
It seems I picked the wrong type, and now burned through more than any possible savings in terms of time energy trying to get that decision reversed.
The thing is, I'm a newbie to this business, and so is everyone else the first time. Apparently Dotster is a newbie as well, because they don't have any business process in place to support correcting a simple mistake.
It should be trivial for them to revoke the certificate (one of the primary features of Certificates), and issue the new one. It's a shame that I can't just get this done, time constraints have forced other action, so I'm just going to get a refund instead.
I should have known better... after all I had been warned...

Never trust version 1.0, live and learn, I guess.
--Mike--
It seems I picked the wrong type, and now burned through more than any possible savings in terms of time energy trying to get that decision reversed.
The thing is, I'm a newbie to this business, and so is everyone else the first time. Apparently Dotster is a newbie as well, because they don't have any business process in place to support correcting a simple mistake.
It should be trivial for them to revoke the certificate (one of the primary features of Certificates), and issue the new one. It's a shame that I can't just get this done, time constraints have forced other action, so I'm just going to get a refund instead.
I should have known better... after all I had been warned...

Never trust version 1.0, live and learn, I guess.
--Mike--
Sunday, February 19, 2006
Home Grown Video
The fact is that home grown video is taking off. For an example that I find hilarious as a fellow Hoosier, check out Lazy Muncie. It's joins Lazy Monday from the West Coast in the spoof wars started by an YouTube posting of a skit called Lazy Sunday on Saturday Night Live. The pool of spoofs will probably grow some more before we're done. The remix culture is alive and well. Eventually we'll get HD hardware, and it'll get used for movies as well.
NBC has since decided they want to take their ball home, like a spoiled child. The common wisdom among my fellow South Shore passengers is that they should follow the Grateful Dead model of marketing, and give a little something to the market.
I'm sure that you'll see some NBC executives before Congress whining about how their God-given right to make money is being infringed because the market doesn't like them anymore... it's just a matter of time.
It's mix, remix, and stir... creative energy at its most fun. Enjoy the ride.
--Mike--
NBC has since decided they want to take their ball home, like a spoiled child. The common wisdom among my fellow South Shore passengers is that they should follow the Grateful Dead model of marketing, and give a little something to the market.
I'm sure that you'll see some NBC executives before Congress whining about how their God-given right to make money is being infringed because the market doesn't like them anymore... it's just a matter of time.
It's mix, remix, and stir... creative energy at its most fun. Enjoy the ride.
--Mike--
Saturday, February 18, 2006
Blogging Meta - revised
There is a subtle yet profound difference between blogs and previous methods of communicating on the net. Blogs are anchored to a location, which requires ownership. This difference is the major factor which lead to it's current popularity. Unlike email, you can't forge entries from a blog. This allows trusted relationships.
When you read a blog for the first time, you're deciding if you like the author or not. This uses our natural instincts for deciding who we want to build relationships with. It grows over time. You'll develop a set of favorites that you read over time.
When someone makes their list of favorites available, it's a blogroll. When you put someone on your blogroll, it's more than just a person reference, it becomes an endorsement. This means that people think twice before adding someone to a blogroll... which helps keep the quality up.
Blogrolls and easier tools made blogging popular. This lead to the current rush of traffic. All because of the ownership and identity and relationships inherent in the simple fact of a URL anchor.
The tools make it dead easy to link to other blogs, and build the live web. This means that the sheer amount of stuff to discover will probably continue to grow for quite some time. However, this presents the problem of data overload.
The solution that Doc Searls uses is to "aggressively subscribe to RSS searches". I see a danger in that because it breaks the mold of relationships that got us here.
When we were strictly manually building blogrolls, any spam blogs (splogs) that arose would quickly be discounted, and just not added to the growing web of links. This is the only form of spam defense which isn't likely to be overwhelmed in the near future. It's pretty much 100% effective.
When you rely on a search engine to find things for you, you're making a tradeoff. You're taking input from a far larger range of sources, but you loose the inherent filtering present from relationships. This is where the opening comes for spam blogs.
We can either shun search engines, or possibly find ways to make the relationships more explicit so then can be machine readable. If the search engine could factor in your web of trusted relationships, it could then help you manage a much larger group of "friends", or more appropriately non-spammmers.
It remains to be seen if this is a good idea or not. I've revised this since it's original post, I hope this is a lot clearer.
--Mike--
When you read a blog for the first time, you're deciding if you like the author or not. This uses our natural instincts for deciding who we want to build relationships with. It grows over time. You'll develop a set of favorites that you read over time.
When someone makes their list of favorites available, it's a blogroll. When you put someone on your blogroll, it's more than just a person reference, it becomes an endorsement. This means that people think twice before adding someone to a blogroll... which helps keep the quality up.
Blogrolls and easier tools made blogging popular. This lead to the current rush of traffic. All because of the ownership and identity and relationships inherent in the simple fact of a URL anchor.
The tools make it dead easy to link to other blogs, and build the live web. This means that the sheer amount of stuff to discover will probably continue to grow for quite some time. However, this presents the problem of data overload.
The solution that Doc Searls uses is to "aggressively subscribe to RSS searches". I see a danger in that because it breaks the mold of relationships that got us here.
When we were strictly manually building blogrolls, any spam blogs (splogs) that arose would quickly be discounted, and just not added to the growing web of links. This is the only form of spam defense which isn't likely to be overwhelmed in the near future. It's pretty much 100% effective.
When you rely on a search engine to find things for you, you're making a tradeoff. You're taking input from a far larger range of sources, but you loose the inherent filtering present from relationships. This is where the opening comes for spam blogs.
We can either shun search engines, or possibly find ways to make the relationships more explicit so then can be machine readable. If the search engine could factor in your web of trusted relationships, it could then help you manage a much larger group of "friends", or more appropriately non-spammmers.
It remains to be seen if this is a good idea or not. I've revised this since it's original post, I hope this is a lot clearer.
--Mike--
Friday, February 17, 2006
The Blogging Meta
This post rambles wayyy too much, as Dave points out in the comments. Skip it, and read the next one instead. --Mike--
The history of the internet is rich in details and many examples of technologies that have come and gone. The overall pattern is one of new systems solving the problems of older technologies, then winning popularity. Sometimes the advantages of the new system are readily apparent, and at other times the differences weren't so easy to spot.
I'm writing this in an attempt to highlight what I think are the reasons for the popularity of blogging up to this point, and to help provide a wider foundation for discussion about future directions it might take.
Blogging is a relatively new form of social networking to appear on the internet. The owner of a blog makes a series of posts about topics they find interesting, on a regular basis. The entries are usually titled and dated, and presented in reverse chronological order. The entries are usually in the form of commentary on other blogs, web content, news of the day, person observations, or centered on some theme.
There is a subtle yet profound difference between blogs and previous methods of communicating on the net. Blogs are anchored to a location, which requires ownership. This difference is the major factor which lead to it's current popularity.
Now... you might just think I'm full of shit, but consider this:
When you read a blog for the first time, you're deciding if you like the author or not. This is a personal relationship based on ownership and content of the blog. It grows over time. You'll develop a set of favorites that you read over time.
When someone makes their list of favorites available, it's a blogroll. When you put someone on your blogroll, it's more than just a person reference, it becomes an endorsement. This means that people think twice before adding someone to a blogroll... which helps keep the quality up.
Blogrolls and easier tools made blogging popular. This lead to the current rush of traffic. All because of the ownership and identity and relationships inherent in the simple fact of a URL anchor.
The tools make it dead easy to link to other blogs, and build the live web. This means that the sheer amount of stuff to discover will probably continue to grow for quite some time.
When we were strictly manually building blogrolls, any spam blogs (splogs) that arose would quickly be discounted, and just not added to the growing web of links. This is the only form of spam defense which isn't likely to be overwhelmed in the near future. It's pretty much 100% effective.
Now that the search engine tools are arriving, we're starting to hear about splogs. This is due to the fact that the seach engines lack the reputation metadata that is inherent in blogrolls and the personal discernment of content quality. We need to find a way to supply this metadata, or create a suitable replacement.
That is the challenge we face, to build search engines that can use reputation to moderate out spam before it gets a chance to grow. It has to be based on relationships, and identity. If there's any way that it can get gamed, it will, so we need to be very careful.
At this point, I bow to the collective wisdom of you, gentle reader, and the rest of the community. I'm open for any and all suggestings that don't spam me. 8)
I thank you for your time, and I hope you found some new thoughts to consider.
--Mike--
The history of the internet is rich in details and many examples of technologies that have come and gone. The overall pattern is one of new systems solving the problems of older technologies, then winning popularity. Sometimes the advantages of the new system are readily apparent, and at other times the differences weren't so easy to spot.
I'm writing this in an attempt to highlight what I think are the reasons for the popularity of blogging up to this point, and to help provide a wider foundation for discussion about future directions it might take.
Blogging is a relatively new form of social networking to appear on the internet. The owner of a blog makes a series of posts about topics they find interesting, on a regular basis. The entries are usually titled and dated, and presented in reverse chronological order. The entries are usually in the form of commentary on other blogs, web content, news of the day, person observations, or centered on some theme.
There is a subtle yet profound difference between blogs and previous methods of communicating on the net. Blogs are anchored to a location, which requires ownership. This difference is the major factor which lead to it's current popularity.
Now... you might just think I'm full of shit, but consider this:
When you read a blog for the first time, you're deciding if you like the author or not. This is a personal relationship based on ownership and content of the blog. It grows over time. You'll develop a set of favorites that you read over time.
When someone makes their list of favorites available, it's a blogroll. When you put someone on your blogroll, it's more than just a person reference, it becomes an endorsement. This means that people think twice before adding someone to a blogroll... which helps keep the quality up.
Blogrolls and easier tools made blogging popular. This lead to the current rush of traffic. All because of the ownership and identity and relationships inherent in the simple fact of a URL anchor.
The tools make it dead easy to link to other blogs, and build the live web. This means that the sheer amount of stuff to discover will probably continue to grow for quite some time.
When we were strictly manually building blogrolls, any spam blogs (splogs) that arose would quickly be discounted, and just not added to the growing web of links. This is the only form of spam defense which isn't likely to be overwhelmed in the near future. It's pretty much 100% effective.
Now that the search engine tools are arriving, we're starting to hear about splogs. This is due to the fact that the seach engines lack the reputation metadata that is inherent in blogrolls and the personal discernment of content quality. We need to find a way to supply this metadata, or create a suitable replacement.
That is the challenge we face, to build search engines that can use reputation to moderate out spam before it gets a chance to grow. It has to be based on relationships, and identity. If there's any way that it can get gamed, it will, so we need to be very careful.
At this point, I bow to the collective wisdom of you, gentle reader, and the rest of the community. I'm open for any and all suggestings that don't spam me. 8)
I thank you for your time, and I hope you found some new thoughts to consider.
--Mike--
Web 2.0 requires reputation
Don Marti looks at the LiveWeb and RSS, and sees history rhyming with itself, and predicts a repeat of Usenet.
We can learn from history and avoid the mistakes. I don't believe that we're really looking for threads, so I think we'll avoid a repeat of Usenet inspite of ourselves. The current LiveWeb (Web 2.0) is an artifact not of the reading software, as Don suggests, but rather of the structure of blogging in general.
A blog is generally the output of a single person or a small group. The result is that the blog has an inherent identity and reputation associated with each and every single post. The biggest problem with usenet is that these two items were left out. (This is also why spam plagues email, the "from" address is just a variable)
All of these forms of communciation can be mapped into each other, if you look at things from a meta-level. If we all do what Doc is doing, en mass, and just doing keyword searches, we'll quickly be back where we started, and Don's prediction will come true.
My interpretation is that what we really want is to be able to find interesting stuff, add some things to it, and share it with others. The essential key to everything is to avoid spam. If we insist that some form of reputation is absolutely necessary for what we allow in to Web 2.0, we'll lick the problem, and have learned our lesson.
Technorati comes close to some vague ideals sitting in the back of my brain with Tagging. As I've pointed out before, it doesn't quite get there. We want to add value... allowing readers to actively add tags is a big way of adding value. The folks at Technorati would be insane to do it without one crucial ingredent... keeping reputation with the data.
This allows us to filter out spammers as we find them, without having to re-read everything on the web, in order to re-build the "authority" database. In real life, we always take whats said along with who said it as a pair. With mass media, and aggregation, an imporant part of the equation is lost. We need to prevent it from happening again.
Let's keep our reputations. Let's keep the Live Web just that... a Web of Live people we can relate to. What is said is never separate from who said it.
Thank you for your time and attention.
--Mike--
PS: I've since posted another view of this.
We can learn from history and avoid the mistakes. I don't believe that we're really looking for threads, so I think we'll avoid a repeat of Usenet inspite of ourselves. The current LiveWeb (Web 2.0) is an artifact not of the reading software, as Don suggests, but rather of the structure of blogging in general.
A blog is generally the output of a single person or a small group. The result is that the blog has an inherent identity and reputation associated with each and every single post. The biggest problem with usenet is that these two items were left out. (This is also why spam plagues email, the "from" address is just a variable)
All of these forms of communciation can be mapped into each other, if you look at things from a meta-level. If we all do what Doc is doing, en mass, and just doing keyword searches, we'll quickly be back where we started, and Don's prediction will come true.
My interpretation is that what we really want is to be able to find interesting stuff, add some things to it, and share it with others. The essential key to everything is to avoid spam. If we insist that some form of reputation is absolutely necessary for what we allow in to Web 2.0, we'll lick the problem, and have learned our lesson.
Technorati comes close to some vague ideals sitting in the back of my brain with Tagging. As I've pointed out before, it doesn't quite get there. We want to add value... allowing readers to actively add tags is a big way of adding value. The folks at Technorati would be insane to do it without one crucial ingredent... keeping reputation with the data.
This allows us to filter out spammers as we find them, without having to re-read everything on the web, in order to re-build the "authority" database. In real life, we always take whats said along with who said it as a pair. With mass media, and aggregation, an imporant part of the equation is lost. We need to prevent it from happening again.
Let's keep our reputations. Let's keep the Live Web just that... a Web of Live people we can relate to. What is said is never separate from who said it.
Thank you for your time and attention.
--Mike--
PS: I've since posted another view of this.
Thursday, February 16, 2006
A real security model, spotted in the wild!
Jeff Atwood of Coding Horror hits the jackpot:
This is what we're going to have to do for everything. Why trust code, when you can just run it in a sandbox?
It's great to see something I've been trying to communicate layed out in such a straight forward manner... I strongly suggest you read the whole thing.
Too many scary vulnerabilities in crusty old IE6? You can't stop clicking on dancing bunnies? Just run your OS session in a virtual machine. At the end of every session, you blow it away. No spyware or virus is virulent enough to escape a VM. If you want to log in again, you tear off a new VM and start fresh. It's like formatting your hard drive every time you turn off your PC. And this doesn't have to be done at the OS level to be beneficial, either; why not selectively launch apps in their own private VMs?
This is what we're going to have to do for everything. Why trust code, when you can just run it in a sandbox?
It's great to see something I've been trying to communicate layed out in such a straight forward manner... I strongly suggest you read the whole thing.
Wednesday, February 15, 2006
Technorati musings - part 2
In my previous post, I suggested opening up Technorati, or other search engines, to allow third party data to be aggregated into a mix. Done most efficiently, this would still result in the need to create and manage a massive continous flow of data between services.
One of the points which I apparently didn't make very well, was a new concept of the Active Reading of blogs. If the reader of a blog were allowed to contribute metadata about it, powerful new capabilities fall out like rain.
Imagine a FireFox extension which allowed you to quickly give a blog entry you just read a tag... or set of tags. The reader offers a new perspective, and as an author, your active audience is just who you want to rate you. They will notice that your posting needs a certain tag for you, and could take care of it for you. They will make connections and links you might never have considered.
Active Reading requires some infrastructure to pull it off.... which I don't want to understate.
Mechanics
Active Reading would result in a new flow of records, with the following fields:
Once this data gets gathered, you could then do a search and get far more accurate tagging, and rating to help get the best content to the top.
A new service would be to be able to subscribe to all of the posts a reader found insightful, or related to a given tag. For example, it would be nice to be able to subscribe to everything Doc Searls read, and chose to tag as Web2.0.
Once this data gets massaged, sorted, merged it starts to become useful. The amount of data that can be generated by a popular Web 2.0 application is staggering. According to David Sifry, Technorati tracks 50,000 posts per hour... and it should be easy to match that rate with reader tagging... imagine it!
It would take some bandwidth, but the end results could be spectacular. I believe this could actually help us get rid of blog spam, once and for all. Active participation as a blog reader would be a novelty at first, but could become quite an art form in and of itself.
Long term, this could lead even further to allowing 3rd party markup of content, which would finally get us to the vision that started the web in the first place, a truely read-write web.
It'll take good engineering, but the rewards should be worth it.
One of the points which I apparently didn't make very well, was a new concept of the Active Reading of blogs. If the reader of a blog were allowed to contribute metadata about it, powerful new capabilities fall out like rain.
Imagine a FireFox extension which allowed you to quickly give a blog entry you just read a tag... or set of tags. The reader offers a new perspective, and as an author, your active audience is just who you want to rate you. They will notice that your posting needs a certain tag for you, and could take care of it for you. They will make connections and links you might never have considered.
Active Reading requires some infrastructure to pull it off.... which I don't want to understate.
Mechanics
Active Reading would result in a new flow of records, with the following fields:
- Permalink
- Reviewer Identity
- TimeStamp
- Metadata
Once this data gets gathered, you could then do a search and get far more accurate tagging, and rating to help get the best content to the top.
A new service would be to be able to subscribe to all of the posts a reader found insightful, or related to a given tag. For example, it would be nice to be able to subscribe to everything Doc Searls read, and chose to tag as Web2.0.
Once this data gets massaged, sorted, merged it starts to become useful. The amount of data that can be generated by a popular Web 2.0 application is staggering. According to David Sifry, Technorati tracks 50,000 posts per hour... and it should be easy to match that rate with reader tagging... imagine it!
It would take some bandwidth, but the end results could be spectacular. I believe this could actually help us get rid of blog spam, once and for all. Active participation as a blog reader would be a novelty at first, but could become quite an art form in and of itself.
Long term, this could lead even further to allowing 3rd party markup of content, which would finally get us to the vision that started the web in the first place, a truely read-write web.
It'll take good engineering, but the rewards should be worth it.
Tuesday, February 14, 2006
Technorati through the 8th Dimension
Technorati needs to add some more dimensions. They have two that I'm aware of at present:
There are many other quantities of a page that could be measured, and made externally available as a control adjustment, especially the spam dimension.
To add further value, Tagging is a way of adding dimensions, but it's binary... present or not. The worse problem is that the source of the tag is limited to the author... which invites more gaming of the system again. 8(
It would be far better if the following things happened:
I for one would like to be able to search for all non-spam security blog entries made in the past 24 hours related to keykos or eros. I'd be willing to then tag them to help other people see less noise, and thus a better signal/noise ratio.
I'd be willing to bet a whole lot of people would be willing to be meta-editors, if it were cheap and easy.
Let's build some new tools, and see if we can actually make the world a better place, in spite of ourselves. ;-)
--Mike--
- Authority
- Time
- Pagerank
- Time
There are many other quantities of a page that could be measured, and made externally available as a control adjustment, especially the spam dimension.
To add further value, Tagging is a way of adding dimensions, but it's binary... present or not. The worse problem is that the source of the tag is limited to the author... which invites more gaming of the system again. 8(
It would be far better if the following things happened:
- Provide a way for the audience to tag content
- Provide a way to include a number with the tag (as in 0% kokeshi for a picture of a dog named Kokeshi, for example)
- Make this type of metadata available for mashup
- Build a standard for sharing this type of metadata
- Figure out how to use someone elses public facing metadata in search results.
I for one would like to be able to search for all non-spam security blog entries made in the past 24 hours related to keykos or eros. I'd be willing to then tag them to help other people see less noise, and thus a better signal/noise ratio.
I'd be willing to bet a whole lot of people would be willing to be meta-editors, if it were cheap and easy.
Let's build some new tools, and see if we can actually make the world a better place, in spite of ourselves. ;-)
--Mike--
Monday, February 13, 2006
Thinking about gatekeepers, spam, and metadata
This is a long one... please forgive the length... I'm thinking it out loud as I go.
Doc Searls isn't a gatekeeper... but he does a great service for me, he helps filter out the massive volumes of stuff that is Web 2.0 (or blog-o-sphere... I don't have a good term for it).
I count on Doc to share interesting things he's found related to Web 2.0, Blogging, RSS, Podcasting, and the societal impact thereof. If you want to know how to build a new hierarchy of your own, Doc's the man.
Doc recently pointed out that he subscribes to several keyword searches to keep abreast of the topics he's interested in. In this case, he doesn't use any human gatekeepers, but is relying on the technology as a tool. This allows Doc to get input from a much larger span of sources than any other human could deal with. When you operate this way, you too can get a much broader range of sources, and be much better connected.
Unfortunately there is a big downside to this.... SPAM.
I tried out Doc's approach, because I'm interested in Computer Security. I'm interested in a very special aspect of it though, I'm very pragmatic in that I want to be able to run untrusted code... which makes finding the right keywords almost impossible. Once you do find the right keywords, guess what happens.... you hit the wall-o-spam again....
For example, the search for keykos security at technorati returns 2 results in the past 33 days. The first post is spam, and there's my post right below it. This is a very narrow search, yet spam comes up first. Unless of course I'm wrong and a new blog with no real content named "search engine submission" really isn't spam... ;-)
Points so far:
For example, this very document before your eyes could be generating community metadata as you read it. How much of a page you read, how much time you spent reading it, and when, are all useful bits of knowledge if you have efficient ways to store and index it. I know that I certainly would like to know which parts of this blog are interesting, so that I can improve my writing skills to help get my point across effectively.
I'd like to know exactly what I've read. I'd like to be able to pull that data up, and add some metadata and comments, and rate it. This would be useful for my own reference, and possibly for others as well.
Annotation + Rating
A lot of what Doc Searls does manually by blogging could be interpreted as 3rd party annotation. He points us towards things he finds interesting, along with clues about his opinion of it (agree/disagree/funny/insightful, etc). I believe it would be very useful for the rest of us to do the same in a more automated, tool leveraged way.
The broken promise of Web 1.0 is that HTML doesn't actually allow Markup of Hypertext. We've had to evolve blogs, and commenting about posts, and technorati, and all sorts of other infrastructure just to get to the point where we kinda make up for a basic design error.
In my ideal world, you'd be able to pull up a page, highlight a section of it, and add notes, ratings, links to supporting material or ideas. The correct term for this is Markup, but that's been diluted by the term HTML as to become useless as a search term, so we're forced to use Annotation instead.
Just imagine if you could right-click on any web page and then click "flag as spam". The backside of this would be that you could then know before opening a link, what was spam. It would get really powerful if you could then have this data factored in to your search engine results before you see them.
Just imagine if you could right-click on the same page, and add technorati tags to it... including SPAM. ;-)
We need to be able to do this... the last search engine to do it is a wrotten egg!
Well.. that's a lot of wandering around the topic... more of a brain dump actually....
Thanks for sticking with it, hope you found it interesting.
--Mike--
Doc Searls isn't a gatekeeper... but he does a great service for me, he helps filter out the massive volumes of stuff that is Web 2.0 (or blog-o-sphere... I don't have a good term for it).
I count on Doc to share interesting things he's found related to Web 2.0, Blogging, RSS, Podcasting, and the societal impact thereof. If you want to know how to build a new hierarchy of your own, Doc's the man.
Doc recently pointed out that he subscribes to several keyword searches to keep abreast of the topics he's interested in. In this case, he doesn't use any human gatekeepers, but is relying on the technology as a tool. This allows Doc to get input from a much larger span of sources than any other human could deal with. When you operate this way, you too can get a much broader range of sources, and be much better connected.
Unfortunately there is a big downside to this.... SPAM.
I tried out Doc's approach, because I'm interested in Computer Security. I'm interested in a very special aspect of it though, I'm very pragmatic in that I want to be able to run untrusted code... which makes finding the right keywords almost impossible. Once you do find the right keywords, guess what happens.... you hit the wall-o-spam again....
For example, the search for keykos security at technorati returns 2 results in the past 33 days. The first post is spam, and there's my post right below it. This is a very narrow search, yet spam comes up first. Unless of course I'm wrong and a new blog with no real content named "search engine submission" really isn't spam... ;-)
Points so far:
- We need other people's help to filter Web 2.0 down to size
- Spam is a persistent problem
- Keywords only go so far
- Tagging helps
For example, this very document before your eyes could be generating community metadata as you read it. How much of a page you read, how much time you spent reading it, and when, are all useful bits of knowledge if you have efficient ways to store and index it. I know that I certainly would like to know which parts of this blog are interesting, so that I can improve my writing skills to help get my point across effectively.
I'd like to know exactly what I've read. I'd like to be able to pull that data up, and add some metadata and comments, and rate it. This would be useful for my own reference, and possibly for others as well.
Annotation + Rating
A lot of what Doc Searls does manually by blogging could be interpreted as 3rd party annotation. He points us towards things he finds interesting, along with clues about his opinion of it (agree/disagree/funny/insightful, etc). I believe it would be very useful for the rest of us to do the same in a more automated, tool leveraged way.
The broken promise of Web 1.0 is that HTML doesn't actually allow Markup of Hypertext. We've had to evolve blogs, and commenting about posts, and technorati, and all sorts of other infrastructure just to get to the point where we kinda make up for a basic design error.
In my ideal world, you'd be able to pull up a page, highlight a section of it, and add notes, ratings, links to supporting material or ideas. The correct term for this is Markup, but that's been diluted by the term HTML as to become useless as a search term, so we're forced to use Annotation instead.
Just imagine if you could right-click on any web page and then click "flag as spam". The backside of this would be that you could then know before opening a link, what was spam. It would get really powerful if you could then have this data factored in to your search engine results before you see them.
Just imagine if you could right-click on the same page, and add technorati tags to it... including SPAM. ;-)
We need to be able to do this... the last search engine to do it is a wrotten egg!
Well.. that's a lot of wandering around the topic... more of a brain dump actually....
Thanks for sticking with it, hope you found it interesting.
--Mike--
Sunday, February 12, 2006
Feeding the long tail
Today's bit of wisdom comes from Scott Karp at "Publishing 2.0":
Amen! It doesn't take much at all, a link here or there, a mention or two, and we in the long tail stay happy, and keep plugging away at it. If you want to think of it as building a market, or building a community, or better yet, building a society, please do so.
I'm of the solid opinion that the larger the blog-o-sphere, the better we all are. It helps us face down one of the three biggest issues facing Democracy, which is a good thing.
--Mike--
Consumer-created media takes a lot of time and energy — unless we develop economic models to meaningfully compensate the long tail, the ego payoff for most people won’t be enough to justify the effort. The cost of entry to create content is low in terms of dollars, but the cost of sustainable content creation is very high in terms of time, which in this short life is our most valuable commodity.
Amen! It doesn't take much at all, a link here or there, a mention or two, and we in the long tail stay happy, and keep plugging away at it. If you want to think of it as building a market, or building a community, or better yet, building a society, please do so.
I'm of the solid opinion that the larger the blog-o-sphere, the better we all are. It helps us face down one of the three biggest issues facing Democracy, which is a good thing.
--Mike--
Gatekeeper? Bah humbug
The "A-list" is an artifact of popularity. Popularity is the result of... being popular.... which is usually the result of hard work and merit.
We all have an equal opprotunity to do the hard work of writing well, and often. Just because they make it look easy, don't let that blind you to the skill and effort it takes. We all want equal opprotunity, not equal results.
Mike Warot - at #171,461 in Technorati's Long Tail as of now, and not whining about it.
We all have an equal opprotunity to do the hard work of writing well, and often. Just because they make it look easy, don't let that blind you to the skill and effort it takes. We all want equal opprotunity, not equal results.
Mike Warot - at #171,461 in Technorati's Long Tail as of now, and not whining about it.
Saturday, February 11, 2006
Testing 1 2 3 - Doc Searls are you there?
This is a test, a test to see if Doc Searls actually listens to the long tail, and to see how long it takes. Now, I'm not going to do anything other than post this message which mentions his name, the long tail, and a subject he's near and dear to... the A-list and Gatekeepers.
Note: Doc, see the bold text below if you read this.
Why? Well, I'm curious, more than anything else. Doc strikes me as a good guy, who happens to be towards the top of the "long tail" of blogging.
There's another reason for this post... to reply (without hyperlinking to it... yikes).. to his post of February 11th entitled "Offensive Post". See, Doc is in a bad spot. He's accused of being a gatekeeper, merely because he's an "A-lister"... which is a no-win proposition... but it's all the wrong question.
The blog-o-sphere, web 2.0, or whatever the heck you want to call this mess of cluetrain, blogging, RSS, Technorati, and all of it... is different than many other things because the tools make it equal opprotunity. (Don't whine about unequal results, that's a matter of working at it!) I'm writing this at 11:30 PM CST on February 11, 2006. I'm fairly certain that Doc Searls will see and read this posting, without hyperlinking to his site (which would kick off a trackback or referal log)... all because of the nature of feeds he reads.
Now, Doc's read and written to me in the past, but it's not a daily thing... so knowing my reputation might give it a bit of a boost.... but not much. (No delusions of grandure here)
It'll be interesting to see exactly how, and how long, it takes.
Why do I care? Why should you? Because, if Doc is typical of the way things are going, the A-list is going to matter less and less, just as the blogrolls are becoming old news. We'll keep some daily reads, but we'll be filtering on subjects instead of authority. This completely eliminates hierarchy and replaces it with taxonomy (or tags, or whatever you want to call it today).
Thanks for your time and attention.
Note: Doc, see the bold text below if you read this.
Why? Well, I'm curious, more than anything else. Doc strikes me as a good guy, who happens to be towards the top of the "long tail" of blogging.
There's another reason for this post... to reply (without hyperlinking to it... yikes).. to his post of February 11th entitled "Offensive Post". See, Doc is in a bad spot. He's accused of being a gatekeeper, merely because he's an "A-lister"... which is a no-win proposition... but it's all the wrong question.
The blog-o-sphere, web 2.0, or whatever the heck you want to call this mess of cluetrain, blogging, RSS, Technorati, and all of it... is different than many other things because the tools make it equal opprotunity. (Don't whine about unequal results, that's a matter of working at it!) I'm writing this at 11:30 PM CST on February 11, 2006. I'm fairly certain that Doc Searls will see and read this posting, without hyperlinking to his site (which would kick off a trackback or referal log)... all because of the nature of feeds he reads.
Now, Doc's read and written to me in the past, but it's not a daily thing... so knowing my reputation might give it a bit of a boost.... but not much. (No delusions of grandure here)
It'll be interesting to see exactly how, and how long, it takes.
Why do I care? Why should you? Because, if Doc is typical of the way things are going, the A-list is going to matter less and less, just as the blogrolls are becoming old news. We'll keep some daily reads, but we'll be filtering on subjects instead of authority. This completely eliminates hierarchy and replaces it with taxonomy (or tags, or whatever you want to call it today).
Thanks for your time and attention.
Thursday, February 09, 2006
Free lunch?
John Thorne, a Verizon senior vice president and deputy general counsel, got it backwards. According to the Washington Post, he said:
Such is the world of doublespeak and boldface lying that inhabits the beltway. It's obscene.
--Mike--
The network builders are spending a fortune constructing and maintaining the networks that Google intends to ride on with nothing but cheap serversNow, in my view of the world... things are a little different... he should have said:
It is enjoying a free lunch that should, by any rational account, be the lunch of the facilities providers.
The internet builders are spending a fortune constructing and maintaining the services that we indend to exploit with nothing but our old depreciated infrastructure.
We're enjoying a $200 Billion lunch that should, by any rational account, be the lunch of our customers.
Such is the world of doublespeak and boldface lying that inhabits the beltway. It's obscene.
--Mike--
Wednesday, February 08, 2006
State of Security - 2006
Dan Farber reports on the state of CyberSecurity in 2006 at Demo.
I have my own State of Security speach in mind.....
My Friends, we the state of CyberSecurity is very weak.
Our mainstream Operating Systems ignore research from the 1960s and 70s and persist in using a broken security model.
Our OS vendors worry about features and PR instead of security
Our users have grown accustomed to repeatedly being threatened with weapons of mass destruction which would not be possible with a secure computing model.
We face many threats, the largest of which are inerta, and our own mass ignorance.
The solutions offered are inadequate at best, and only a temporary measure.
Virus scanners and network filters won't work.
Security updates won't work.
Signed code won't work.
Managed code won't work.
"Trusted Computing" won't work.
Teaching students to write "secure programs" won't work (but it will help for other reasons)
Locking existing OSs down is only a stopgap.
The good news is that there are measures that will work. (see note below)
So you see, the day will come when We don't have to be afraid.
We will build operating systems that are fast, stable and secure. We'll be able to run any program from anyone, without fear. We'll be able to experiment and mix and match programs like never before.
The road ahead won't be easy. There will be miles to go, and may large challenges to meet, but we will get there. We will eliminate the need for virus scanners and anti-spyware programs. A pleasant side-effect will be the complete prohibition of DRM.
Please join me in my goal is to see a secure OS by 2010. Let's make it free and open source.
--Mike--
How? Here's how:
The key to security is to lock every application in a virtual machine. Now that both Intel and AMD seem to have realized just how important it is to be able to do real virtualization, this will radically drive down the cost of implementing a virtual machine, in terms of code, and especially performance.
We went through all these lessons with IBM's VM systems back in the 1960s and 1970s. You can't trust anything that isn't the operating system kernel and the hardware. And you can only trust them if they get see a lot of use and get watched like a hawk by the good guys.
I have my own State of Security speach in mind.....
My Friends, we the state of CyberSecurity is very weak.
Our mainstream Operating Systems ignore research from the 1960s and 70s and persist in using a broken security model.
Our OS vendors worry about features and PR instead of security
Our users have grown accustomed to repeatedly being threatened with weapons of mass destruction which would not be possible with a secure computing model.
We face many threats, the largest of which are inerta, and our own mass ignorance.
The solutions offered are inadequate at best, and only a temporary measure.
Virus scanners and network filters won't work.
Security updates won't work.
Signed code won't work.
Managed code won't work.
"Trusted Computing" won't work.
Teaching students to write "secure programs" won't work (but it will help for other reasons)
Locking existing OSs down is only a stopgap.
The good news is that there are measures that will work. (see note below)
So you see, the day will come when We don't have to be afraid.
We will build operating systems that are fast, stable and secure. We'll be able to run any program from anyone, without fear. We'll be able to experiment and mix and match programs like never before.
The road ahead won't be easy. There will be miles to go, and may large challenges to meet, but we will get there. We will eliminate the need for virus scanners and anti-spyware programs. A pleasant side-effect will be the complete prohibition of DRM.
Please join me in my goal is to see a secure OS by 2010. Let's make it free and open source.
--Mike--
How? Here's how:
The key to security is to lock every application in a virtual machine. Now that both Intel and AMD seem to have realized just how important it is to be able to do real virtualization, this will radically drive down the cost of implementing a virtual machine, in terms of code, and especially performance.
We went through all these lessons with IBM's VM systems back in the 1960s and 1970s. You can't trust anything that isn't the operating system kernel and the hardware. And you can only trust them if they get see a lot of use and get watched like a hawk by the good guys.
Long term thinking
One of the things I've noticed now that I blog more is that my attention has shifted away from community sites like Slashdot. I still use it as an early warning system for threats to my day job, but I comment there far less than I used to.
Today's story was about the next generation of ethernet, 100Gigabit. The comments from the crowd at /. were familiar and quite predictible:
Fast forward to today, I routinely move Gigabyte files around the LAN, and am thankful for Gigabit Ethernet. Now, in the space of 20 years we've gone from no networking to Gigabit, so it's reasonable to expect we'll need more bandwidth in the future. It's obvious that we're eventually going to find something to eat up 100Gbit/second. I could do it very easily today, if I had access to enough disk space, it's called hi-definition video.
Record a few hours of 1080i/59.94 video each day. Then decide you need to make backups. You now need a network connection, and "FireWire" isn't anywhere near quick enough. You'll always be looking for a fatter pipe, always.
That's just the obvious and somewhat extreme example. I have no idea what kind of stuff we'll be moving around 10 or 20 years from now, but I'm dead certain it will be HUGE compared to the stuff we do now.
Long term thinking allows you to pull back from the immediate response, and put this in perspective. We'll always find a use for more power, and we'll never be sated. The /. responses in this case are more reactive, and lack this long term thinking.
I'm shifting my mindset, slowly over time. I believe it's for the better.
--Mike--
Today's story was about the next generation of ethernet, 100Gigabit. The comments from the crowd at /. were familiar and quite predictible:
- we'll never need it
- nobody will buy it
Fast forward to today, I routinely move Gigabyte files around the LAN, and am thankful for Gigabit Ethernet. Now, in the space of 20 years we've gone from no networking to Gigabit, so it's reasonable to expect we'll need more bandwidth in the future. It's obvious that we're eventually going to find something to eat up 100Gbit/second. I could do it very easily today, if I had access to enough disk space, it's called hi-definition video.
Record a few hours of 1080i/59.94 video each day. Then decide you need to make backups. You now need a network connection, and "FireWire" isn't anywhere near quick enough. You'll always be looking for a fatter pipe, always.
That's just the obvious and somewhat extreme example. I have no idea what kind of stuff we'll be moving around 10 or 20 years from now, but I'm dead certain it will be HUGE compared to the stuff we do now.
Long term thinking allows you to pull back from the immediate response, and put this in perspective. We'll always find a use for more power, and we'll never be sated. The /. responses in this case are more reactive, and lack this long term thinking.
I'm shifting my mindset, slowly over time. I believe it's for the better.
--Mike--
Tuesday, February 07, 2006
Tags vs Truthiness?
Dave points out the problems with any kind of popular voting mechanism for discovering truth. Perhaps tagging our links would fare better than just a "straight up or down vote". I know you can certainly be more expressive with tags.
Do you think LinkTagging would do any better?
--Mike--
Do you think LinkTagging would do any better?
--Mike--
LinkTag
According to Technorati, we're writing and linking at an amazing and increasing pace. We're swimming in a sea of material, but don't have the tools to find the good stuff.
Tagging content as it is written is a good and growing thing. This places the responsiblity for correctly guessing which tags belong on a given posting with the author.
When we link to the posting, we might have different ideas of where it belongs, some new invented tag might be appropriate to it, but we don't have control over the source, we can't annotate it, and the search engines don't provide any way to measure our intentions.
I propose that a new tagging format, a LinkTag be created which would allow us to add this new information when we build links to a posting. If someone decides 3 years from now that this particular posting needs a new tag as they write about it, I certainly can't be expected to anticipate it and pick the exactly correct technorati tag from the future, but the person doing the linking definitely could!
I believe this form of community moderation and markup could be a very powerful and expressive thing. There are opprotunities and dangers aplenty here.... we need to build it, and see where it goes!
Thanks for your time and attention.
--Mike--
Tagging content as it is written is a good and growing thing. This places the responsiblity for correctly guessing which tags belong on a given posting with the author.
When we link to the posting, we might have different ideas of where it belongs, some new invented tag might be appropriate to it, but we don't have control over the source, we can't annotate it, and the search engines don't provide any way to measure our intentions.
I propose that a new tagging format, a LinkTag be created which would allow us to add this new information when we build links to a posting. If someone decides 3 years from now that this particular posting needs a new tag as they write about it, I certainly can't be expected to anticipate it and pick the exactly correct technorati tag from the future, but the person doing the linking definitely could!
I believe this form of community moderation and markup could be a very powerful and expressive thing. There are opprotunities and dangers aplenty here.... we need to build it, and see where it goes!
Thanks for your time and attention.
--Mike--
Monday, February 06, 2006
Expressive Linking
In my previous gut reaction post, I noticed that we need a richer set of expressions that can be encoded along with a link.
For example, if I wish to have a blogroll, I might want to include ratings of one type or another as part of the link. Here are some examples that would be inside the A HREF= link
I've looked at VoteLinks, and they seem to be fairly limited in their scope, for example.
Let's talk about some of the flags that might get used to do more than tag a link, but also help to place its credibility, trust, likelyhood of being spam, authority (cringe), etc. The more data we can include with a link, the more useful they can be.
Of course, nothing is as good as honest markup (aka annotation)... but we'll probably never have that because of spam issues.
It wouldn't be too hard to get this stuff included in new releases of blogging and html editors if it took off. We can make it human editable fairly easy as well.
I've had this bug up my butt for years... as I said 2 years ago in a comment on Aaron's blog:
--Mike--
For example, if I wish to have a blogroll, I might want to include ratings of one type or another as part of the link. Here are some examples that would be inside the A HREF= link
- agreement="100%"
- agreement="0%"
- trust="10%"
- nofollow agreement="0%"
- flamebait="100%"
- humor="100%"
I've looked at VoteLinks, and they seem to be fairly limited in their scope, for example.
Let's talk about some of the flags that might get used to do more than tag a link, but also help to place its credibility, trust, likelyhood of being spam, authority (cringe), etc. The more data we can include with a link, the more useful they can be.
Of course, nothing is as good as honest markup (aka annotation)... but we'll probably never have that because of spam issues.
It wouldn't be too hard to get this stuff included in new releases of blogging and html editors if it took off. We can make it human editable fairly easy as well.
I've had this bug up my butt for years... as I said 2 years ago in a comment on Aaron's blog:
What does everyone else think?How about slashdot as model for discovering the truth? It only takes one meta-tweak to make it so. Allow voting on a number of dimensions, including Humor, Truth, Accuracy, Flame/Constructive, and anything else someone dreams up (including CowboyNealNess), on a -5 to 5 scale.
Or… get a real MARKUP language, and allow people to markup existing debates with their own layers of commentary and gloss on top of it, along with TML (Truth Markup Language), and things of that ilk. The same text could host thousands of discussions all selectively visible.
Even more radical would be the possibility of selectively filterng your worldview to exclude things you don’t believe, automatically, or actively finding things which you wish to ponder because they are near the edge of your beliefs.
Food for thought, and metathought.
--Mike--
Authority should always be questioned
This country was founded on the idea that power corrupts, and thus needs to be corrected. Thus I agree with Dave and Ethan about the nature of Technorati. It seems that Technorati has been asserting that link counts are a substitute for authority, which is foolish, at best.
In fact, I'd go so far as to suggest a modifier to the link to indicate agreement as a percentage. Or some other way of adding metadata to the link.
--Mike--
In fact, I'd go so far as to suggest a modifier to the link to indicate agreement as a percentage. Or some other way of adding metadata to the link.
--Mike--
Sunday, February 05, 2006
Semantic Web, Where art thou?
Earlier in the week I read this from Doc in response to questions from Dave Rogers.
There is yet another possibility, and I believe the one at play here. It's almost impossible to find out what Doc thinks about a subject without actually reading his whole archive and searching for it. We don't have a semantic web, Doc doesn't do tagging (it's nearest substitute), so it's neigh impossible to find the quote Doc chose to use.
Doc knew about the quote because he had it in his memory. If it were something 10 years old, I doubt even he'd have been able to find it, in order to reference it. We need better tools to organize the massive quantities of stuff we create daily. Pure text search kinda works when you have all of the web to integrate over, because on average someone will have used just the right keywords to get a hit. When you go to a smaller sample size, then the usefulness of text searching goes dramatically downhill.
Now, I don't think it would be an efficient allocation of Doc's time to force him to index all of his archive. I'm not even sure that tagging would help the rest of us. Clearly more discussion and research is needed.
--Mike--
| In March of last year I compared this to rolling snowballs. I brought up the making and changing minds point in that post as well. That very post, by the way, offered evidence of that assertion's validity: |
| A few days ago I pretty much came down on the side of Terry Gross and Fresh Air in that show's abortive conflict with Bill O'Reilly of Fox News, even though I cringed when she made a late hit on O'Reilly after he walked out of the interview... |
| Jay Rosen also chimed in with Bill O'Reilly and the Paranoid Style in News. Jay changed my mind because, as usual, he digs deeper... |
| Either Dave chose to ignore that evidence, or he just dislikes it on other grounds. Like, perhaps, that it's a generalization. Did I suggest that blogging is only about making and changing minds? I don't think so, but I can see why Dave might. He seems to like his truths in literal form, and snarks about my fondness for metaphor. We're different. |
There is yet another possibility, and I believe the one at play here. It's almost impossible to find out what Doc thinks about a subject without actually reading his whole archive and searching for it. We don't have a semantic web, Doc doesn't do tagging (it's nearest substitute), so it's neigh impossible to find the quote Doc chose to use.
Doc knew about the quote because he had it in his memory. If it were something 10 years old, I doubt even he'd have been able to find it, in order to reference it. We need better tools to organize the massive quantities of stuff we create daily. Pure text search kinda works when you have all of the web to integrate over, because on average someone will have used just the right keywords to get a hit. When you go to a smaller sample size, then the usefulness of text searching goes dramatically downhill.
Now, I don't think it would be an efficient allocation of Doc's time to force him to index all of his archive. I'm not even sure that tagging would help the rest of us. Clearly more discussion and research is needed.
--Mike--
Thursday, February 02, 2006
Google needs to cut off China
Mike Taht makes a damned good point about Google and China:
I recently wrote about how Google and others should stand up to the new AT&T's attempted extortion. This is exactly the same scenario and I missed that point, until now. AT&T, China, and many other players want to chop up the net, via censorship, metering, differential pricing, and many other ways. But it all boils down to one thing in the end, control.
It's a power play, and Google thought too much, and didn't have enough balls. They need to cut off China, redirect their queries, or do whatever they think is neccessary, but should definitely NOT censor themselves. It is absolutely wrong to deny a people access to their own culture and history.
Google needs to stop appeasement now!
What does Wikipedia got that google doesn't? Balls. And no sissy weasel worded responsibility to the shareholders, only a responsibility to the truth. Google should remember that in part, its responsibility to its shareholders is in being a trusted source for reliable information.Now, Dave wonders about bloggers having their minds changed... I can unequivically say that the following elements changed my mind (because it just happened):
- Mike Taht's posting, with links that let me see the difference
- Doc's pointer and further commentary, especially picking the Orwell reference (otherwise I was going to skip it)
- My own previous posting, in which I examined my own views about Google in a different scenario
I recently wrote about how Google and others should stand up to the new AT&T's attempted extortion. This is exactly the same scenario and I missed that point, until now. AT&T, China, and many other players want to chop up the net, via censorship, metering, differential pricing, and many other ways. But it all boils down to one thing in the end, control.
It's a power play, and Google thought too much, and didn't have enough balls. They need to cut off China, redirect their queries, or do whatever they think is neccessary, but should definitely NOT censor themselves. It is absolutely wrong to deny a people access to their own culture and history.
Google needs to stop appeasement now!
Wednesday, February 01, 2006
AT&T tries Extortion on Web 2.0
It seems that AT&T wants to charge twice for the same traffic... once from their customers, and once more from Google or any other high traffic site they think they can intimidate.
The fix for this problem is very simple. Google should just redirect queries from AT&T customer IP blocks to a special page explaining what is happening, and how they are being threatened. They would, of course still allow the search.
If people smell greedy bastards threatening their Google, they'll react rather quickly and with overwhelming force.
This would be a rather simple, and VERY direct power play. Google, of course, would win. It would do good things for their image as well.
--Mike--
The fix for this problem is very simple. Google should just redirect queries from AT&T customer IP blocks to a special page explaining what is happening, and how they are being threatened. They would, of course still allow the search.
If people smell greedy bastards threatening their Google, they'll react rather quickly and with overwhelming force.
This would be a rather simple, and VERY direct power play. Google, of course, would win. It would do good things for their image as well.
--Mike--
Random thoughts for the day
Noran sent me a link announcing the end of the Western Union Telegram. It had a long run.
I just noticed a line from Dave's blog that tickles me pink, at he bottom of this post:
As well we should!
I just noticed a line from Dave's blog that tickles me pink, at he bottom of this post:
As always, I'm an authority on nothing. I make all this shit up. Do your own thinking.
As well we should!
Subscribe to:
Posts (Atom)
